When the long context came into being, there was a lot of excitement around them. It threatened to disrupt the RAG’s status quo and pumped the hype for MCPs. Of what use is the carefully crafted RAG pipeline to fetch the best document when one can put every document in the context itself. The Frontier Model Labs latched onto the trend. Grok 4.1 was launched with a 2 million context window which made the Gemini 1 million context window look rather ordinary. But these numbers say more about how much text the LLMs can process without breaking. There’s no guarantee that all the context present in such a large window would be actively reasoned. Chroma published a technical report explaining this, naming this phenomenon as Context Rot.
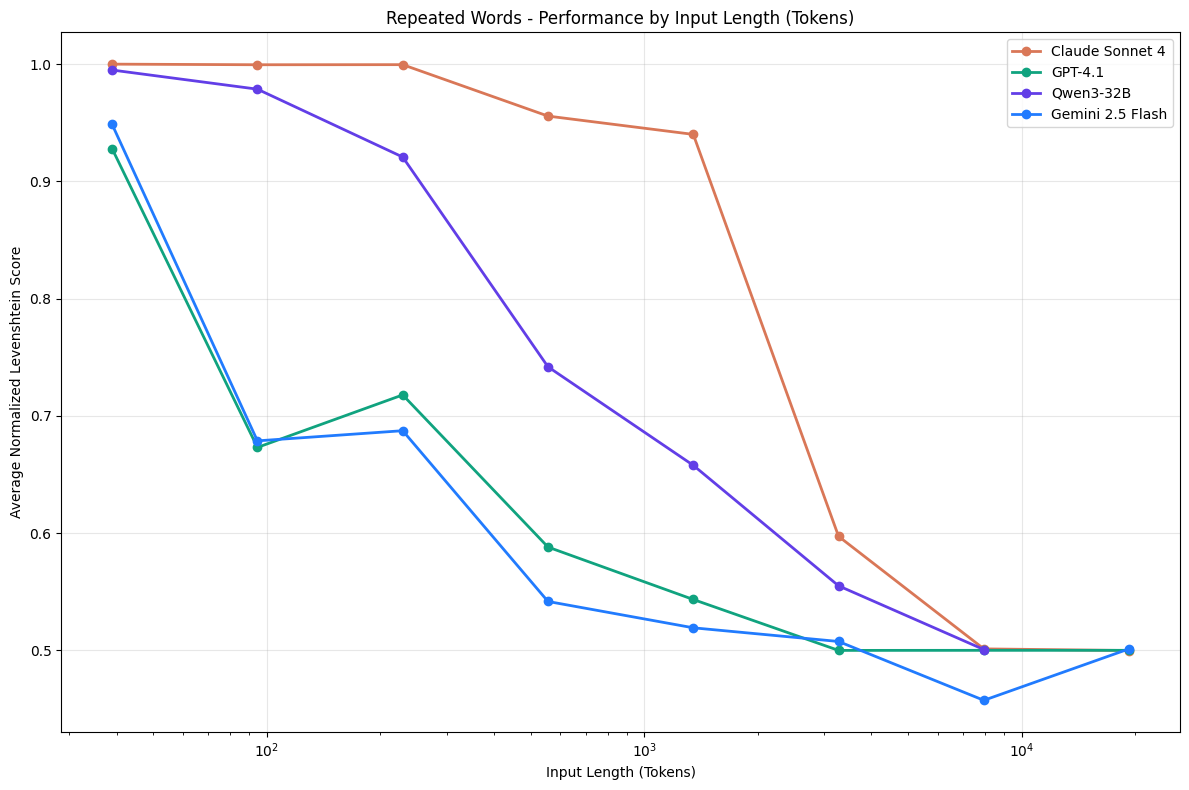
Performance of LLMs as input length grows
While the Context Rot degraded the performance of a simple document QA application, it fundamentally breaks the agentic workflow. While in the static chat interfaces, larger context impacted the quality of the retrieved documents, but in agentic systems, it pollutes the evolving state. To understand this further, one has to understand how does an agent operate on a fundamental level.
The “Agentic” Loop Link to heading
A standard RAG agent operate in a stateless way, where each query is a blank slate (obviously, one can inject the historical context, but it is still a fresh call to the LLM), an agent, on the other hand, relies on a stateful execution loop, where they generate their own context dynamically through iteration. To complete the task at hand, the agent proceeds through a continuous cycle of tool execution:
- Based on the current context, the agent selects an action from a predefined action space.
- The chosen action (a bash command, SQL query etc.) is executed, which produces an observation.
- The action and observation it produced are appended back into the existing context, which forms the input for next iteration.
The above loop continues till the objective is achieved.
This iterative select-execute-append loop in agents significantly alters the underlying compute dynamics. While a standard user-chat experience has more of a “balanced” input to the outputs token ratio, an agentic system is heavily skewed towards prefilling. And, with every iteration the ratio of prefilling to decoding gets more and more skewed.
While the most sane approach is to provide the agent with all the context, in order to maintain state accuracy, we run headfirst into the limitations of long-context models. This design fails as the model fails to weigh the historical execution logs equally.
Limitation of “full” Context Link to heading
The reason for degradation of model performance with increase in context length is rooted in the core mechanics of the Transformer. The Self-Attention block in the Transformer require every token to look at every other token, creating a quadratic compute cost. Hence, creating a quadratic dependency relative to sequence length. For instance, an input of 2 tokens requires a $2\times2$ matrix and scaling the input to 8 tokens would expand the matrix to 64 ($8\times8$) entries.
The alternative architectures have been tried (like state-space models or linear attention variants), but none have replicated the success of Attention mechanism (as evident in the tweet below).
MiniMax M2 Tech Blog 3: Why Did M2 End Up as a Full Attention Model?
— Pengyu Zhao (@zpysky1125) October 29, 2025
On behave of pre-training lead Haohai Sun. (https://t.co/WH4xOD9KrT)
I. Introduction
As the lead of MiniMax-M2 pretrain, I've been getting many queries from the community on "Why did you turn back the clock… https://t.co/DgJjj9lCIw
This makes context engineering only viable path to operational stability.
Techniques Link to heading
1. KV Cache Optimization Link to heading
An autoregressive model in its decoding phase generates a single token at a time. To generate the token $t$, it calculates the attention score between Query ($Q_t$) and keys of all preceding tokens. As the past representation in an autoregressive model are immutable, we can cache the previous keys ($K$) and values ($V$), and focus only on calculating the new ones.The KV Cache can be leveraged if the prompt’s prefix is kept stable. Even a single token change at position $i$ will invalidate entire cache from that point onwards. Context with identical prefix drastically reduces the time-to-first-token (TTFT).
Improving KV cache hit-rate Link to heading
- Keep prefix stable
- Keep the non-varying system prompt and other instructions at the absolute beginning.
- Never place dynamic date (date, user-response etc.) at the start of the prompt.
- Append-only
- Never modify past turns, actions or observations. Only add new data to the end of the sequence.
- It is better to enforce strict, alphabetical key ordering during serialization.
- Design Infrastructure with KV Cache in mind
- Enable
prefix_cachingif using inference frameworks such as vLLM - Employ sticky-sessions to ensure user’s request hits the specific worker holding their warm cache.
- Enable
2. Logit Masking Link to heading
In agentic workflows, tool definitions typically follow the System Prompt. When an observation triggers a state transition requiring fewer tools, the naive solution is to rewrite the prompt to remove them. This discards the existing KV cache and triggers a highly expensive Prefill phase. The solution to this caching penalty is Logit Masking.Instead of altering the input prompt, a more efficient approach is to manipulate the output probabilities (logits) during decoding. The inference server intercepts the raw logits before the softmax layer and applies a mask, forcing the values of forbidden tool tokens to $-\infty$. This mathematically prevents the model from calling the restricted tool ($e^{-\infty} = 0$), even while its definition remains safely in the cached context.
3. grep it all
Link to heading
While KV Cache and Logit Masking optimise the internals of the LLM, working towards better utilisation of the active memory. But, we need not to ingest everything to memory at once. We can externalise the memory entirely to the disk by using FileSystem as context. So, in this design pattern, if the agent needs to understand a system, it must explicitly write an action to search the file system. It reads only the specific file it needs into its active context.This technique works well because System Prompt contains no data. It only contains instructions and tool definitions. If the agent needs any information, it can execute an action to search the file-system and when it learns something new, it can write it to a file, which can be used by succeeding actions. Because we can save all the information externally, we need not to perform complex actions such as context truncation and compression, which no matter how complex the compression logic is, leads to information loss.
4. Negative State Tracking Link to heading
Autoregressive LLMs are memoryless between the API calls. Their entire “memory” comes from the context being passed to them. So, if we remove the errorenous actions taken from the context, the model’s ability to reason fundamentally breaks down. For instance, if the LLM writes a bad SQL query, the database returns a syntax error. If your framework deletes that failed attempt and the error message to keep the prompt clean, the system returns to its exact previous state. Having learned nothing, it will almost certainly generate the exact same bad SQL query again, entering an infinite loop. Keeping the wrong turns in the context transforms a failure into a learnable artifact.
Conclusion Link to heading
The industry’s initial reaction to the problem of context limitation was brute-force infrastructure—larger context windows, larger VRAM clusters, and the hope that the transformer could filter signal from noise. But as agentic workflows demonstrate, stuffing all information into the context window is an anti-pattern. It ignores the reality of self-attention’s structural limits, memory bottlenecks, and context rot. Long context windows are an impressive feat of scaling, but they remain a lazy substitute for clean system design. Context engineering is anything but straightforward; empirical guesswork has become the new SGD. But by mastering it, we stop fighting the quadratic nature of attention.