Non-functional requirements (NFRs) are as important as functional requirements. While the system can still work if the NFRs are not met, it may not meet the stakeholders’ expectations. A functional requirement (FR) defines the specific behaviour of a system, whereas an NFR is a criterion to judge the operation of the system. For instance, a system should show a “list of orders” by the user is defined as a functional requirement, and how much time it takes for a page to load and show the first 10 orders is defined as a non-functional requirement. Hence, NFRs refer to the general qualities that provide a good user experience.
The NFRs are the critical quality attributes that influence the system’s architectural design. Although NFRs are considered essential and critical for software success, there are no agreed-upon guidelines on when and how the NFRs should be elicited and documented. The literature further reduces when it comes to Machine Learning Systems. This post is a humble attempt to fill that gap.
In a traditional software system, one can collect and implement numerous functional requirements. The overall purpose of an ML application is much more focused, like, predicting whether a particular account will churn or not. Thus, there are far fewer functional requirements. Because the functional requirements of an ML system are few, the effective satisfaction of NFRs becomes much more critical.
The NFRs for a Machine Learning System can be of two types, one that applies only to the ML component and the other that applies to the whole system. A requirement like interoperability is only applicable to the machine learning model while scalability will be measured by how the whole system reacts to an increase or decrease in the traffic. The following illustration showcases these two types of NFRs:-
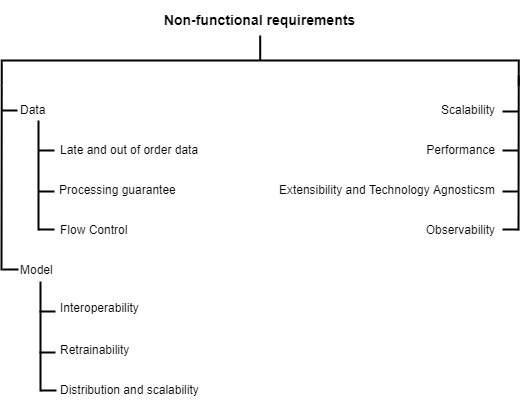
Fig 01 - NFRs for a Machine Learning System
The following sections looks into the above defined NFRs in detail. While there are many other NFRs, like fairness, I will focus only on the NFRs defined above as these are the ones that I have encountered. I will try to update this list, as my experience grows.
ML Specific NFRs Link to heading
1. Data Link to heading
The data is ingested into an ML system in two ways. Either the data is archived in distributed file systems and/or in databases before being fed to the system. Or a capability is developed to process the infinite flowing stream of high-velocity data. As storage is cheaply available these days, storing batch data is not a challenge anymore. Processing batch data is also easier as compared to streaming data because of its finite nature and readily available compute resources (offered by various cloud providers). On the other hand, processing the incoming stream data in real-time or near real-time is a bit more nuanced than batch data processing, as the data is unbounded and might arrive out of order. We can evaluate our stream data pipelines on the following quality attributes, to check if they are working as per required.
1.1. Processing Guarantee Link to heading
This NFR refers to the stream system’s capability to offer processing guarantees, i.e., whether every data sample is processed or not? Processing guarantees come in three flavours, exactly once, at most once, and at least once.
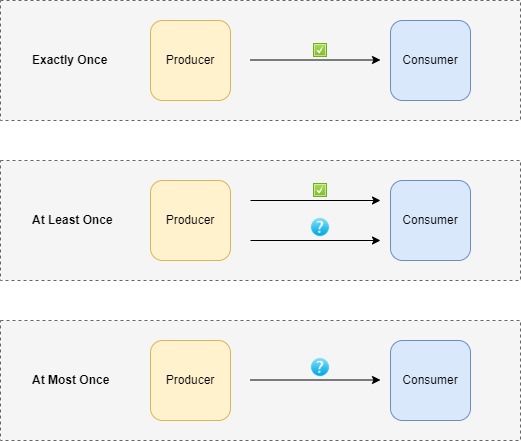
Fig 02 - Types of processing guarantees
While the most desirable guarantee would be exactly once, it does come at an added cost, which translates to latency. This is because it will involve some level of checkpointing to persist state. Hence, will make the system slow. So, it isn’t preferred in every case. Another factor that can play an important role in choice would be how we want our system to react, in case of a failure? As all the modern messaging systems are distributed by nature, a node might crash or go out of memory or any other unforeseen problem arises. How we handle these failures also plays a key role in determining the processing guarantees of a system.
1.2. Late and out-of-order data Link to heading
This NFR refers to the stream system’s capability of processing data that arrive late or in the different order in which it was emitted. A web clickstream could be interrupted if the publisher crashes, which requires the clickstream to be republished or backfilled, leading to data arriving out of order. In order to deal with such a data point, the state of an aggregate must be preserved, so that query can be reprocessed once the data arrives. This is not practical as preserving the state of every aggregate might lead to an out-of-memory error. Hence, some constraints are required to be applied.
To handle the late and out-of-order data, stream systems employ the concept of windowing. Windowing is a process of slicing the data source along temporal boundaries, and it can be of three types, static, sliding, and session.
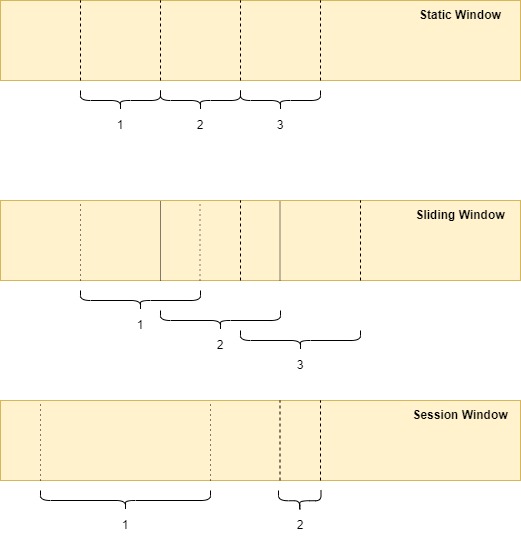
Fig 03 - Type of Windows
Though the windows break down the infinite streaming data into finite windows that can be processed individually, we still need to make sure whether the data that we have in a window is complete or not. For this, the concept of watermarks is applied. Watermarks are the temporal notions of completeness of the input. Conceptually, it is easier to think of watermarks as a mapping from processing time to event time. It asserts that no more data event time less than, say, T, have been observed. Depending upon the use case, the watermarks can be of two types, perfect watermarks where our knowledge of data is certain, and heuristic watermarks, where we make an educated guess.
1.3. Flow Control Link to heading
This NFR measures the system’s capability to handle the situation where the incoming data stream contains way more records than our system can handle. This could happen due to general system delays, and excessive accumulation of data in the buffer, which can lead to a long message queue, and the system tries to process it all in one go. There are multiple strategies for dealing with this backpressure, and one can read about them here.
2. Model Link to heading
The other component of the ML system is the machine learning model itself. Many of the model’s NFRs depends upon the use case itself. There are certain cases where privacy is more important and in some cases, fairness becomes the top priority. In the following sections, we will focus on the three NFRs relating to models, which are fairly common across all the use-cases.
2.1. Retrainability Link to heading
No matter what type of model is being used, be it a tree-based or a neural network, all models go rogue after a certain time. This is because the data changes. Stock markets ebb and wane, new products are launched and pandemics hit. So, our model must adapt to the changing world.
To monitor whether our model’s predictive performance is degrading over time, one can oversee how the underlying data distribution is changing. This change in underlying data distribution is referred to as concept drift.
Apart from monitoring the concept drift, one should also save all the predictions that the model has generated. Measuring the accuracy of a deployed model is an insanely difficult problem. Saving predictions and monitoring the model performance once the ground truths become available can help us in understanding the “real” predictive performance of our model.
2.2. Interoperability Link to heading
Interoperability refers to the ability of two systems to communicate effectively with each other. This NFR is vital in the applications developed for the industries like banking and healthcare. The idea here is to make disparate systems or data work together for an enhanced user experience. For instance, various scans generate a large volume of data for a single patient, which is vastly different from the data logged by doctors during routine checkups. If these two data sources are impossible to integrate, there is no way one can hope for a fast diagnosis of a critical illness.
To bridge the gaps created by an incoherent ecosystem, ONNX was launched. It allows developers to develop models in their preferred framework, without worrying about implications that can arise while inference. One can convert machine learning models trained in any framework to ONNX using ONNXMLTools.
2.3. Distribution and Scalability Link to heading
Certain machine learning use cases, like language translation, question-answering engine, generating images, or playing games require training massive models on enormous datasets. Training these gargantuan models can take a long time and there could be cases where these models might not fit on a single machine. In such cases, the ability to distribute the training to multiple machines and scale the hardware as the need arises can accelerate the training process, and decrease the probability of failure.
A typical machine learning training pipeline consists of feeding the data into a preprocessing pipeline, which prepares it to be readily consumed by the model. The model does a forward pass, computes the loss, and tinkers with the parameters in order to minimize the loss function.
To distribute this whole pipeline, we can break the model into small “functional units”, which are independent in nature and can be recomposed to get the result. These distinct functional units can be executed in parallel to speed up the whole training process. The other way could be to do this on decomposition on the data front, where data is divided into small chunks and multiple machines perform the same computations, but on different data chunks.
System Level NFRs Link to heading
Scalability Link to heading
Scalability is every developer’s dream problem. It generally answers the question that whether the system can handle a spike in traffic while not causing any damage to the user experience.
Scalability is a good problem to have as it communicates loud and clear that everything else is going well. But it is also the trickiest NFR. This is because one is never sure when one should begin to accommodate it in the product architecture. Too early and it might turn out to be a YAGNI (you never gonna need it) situation. Too late and things are beyond repair. So, when one should think about it? There’s a cliche that one should start thinking about scalability before a single line of code is written. According to me, this is not pragmatic. At a very early stage, experimentation with new features should be the top priority. Once the product is stable and one can start making provisions for this NFR. Also, it is very crucial to not take too much technical debt along the way. Following “good” code practices like TDD, uniform code standards, etc. can be really helpful here.
While designing a scalable solution, one can keep the following pointers in mind:-
- Use caching extensively as caching imparts a sense of a highly scalable solution and gives better output in high-demand situations, without wasting computing resources. Based on the situation, one can implement a browser cache or database cache.
- Use Content Delivery Networks (CDN) because they make applications scale faster without any code-level changes.
- Use load balancer and enable auto-scaling. With the advent of the cloud, enabling these services has never been easier.
- Use messaging mechanism of any type of async operations.
Performance Link to heading
Often confused with scalability, this NFR indicates the responsiveness of a system to execute any action within a given interval of time. It deals with the properties like speed, throughput, and responsiveness. To test the performance of the system, one can track metrics like average response time, request rates, and error rates to get a holistic view of how the system is performing.
Flexibility and Technology agnosticism Link to heading
Flexibility or extensibility measures the ability of a system to extend its functionality against the level of effort required to implement the extension. One should avoid vendor lock-ins and keep their system technologically agnostic in order to increase its extensibility coefficient.
Observability or Monitoring Link to heading
Observability is the measure of how well the internal states of a system can be inferred from the knowledge of its external output. High-quality sleep and observability are highly correlated. Implementing observability lets you sleep peacefully at night. Moreover, it helps in tackling bugs faster as it provides us the information to track where they are coming from.
Conclusion Link to heading
In software engineering, there are numerous other NFRs that differ from use-case to use-case. The challenge is not only to identify the right NFRs for your product but also to identify the order in which they are to be implemented. There is no manual for this and this is where experience plays a huge role.