LLMs have been all the rage now. Whether you believe in the potential of LLMs or you are still in the camp of sceptics, it doesn’t matter. It’s the stakeholders’ opinion about LLMs that matters. This is because LLMs make it quite easy to “wow the users” and attract them to the product. So, they facilitate onboarding new users to the product. However, it is the trust that retains the users. And, as most of us know by now, LLMs make numerous mistakes. As the complexity rises and users receive incorrect answers frequently, they won’t trust the system and will revert to the tools they were using before.
This post is my attempt to consolidate the research around LLM evaluation and come up with a loose framework that enhances the trustworthiness of LLM-powered applications.
1. Why traditional evaluation framework won’t work? Link to heading
When we developed Machine Learning models in the pre-LLM era (BC can now be Before ChatGPT), we had a precise checklist which formed our evaluation framework. We divided our input dataset into training, evaluation and test sets and measured the performance by calculating metrics on these datasets.
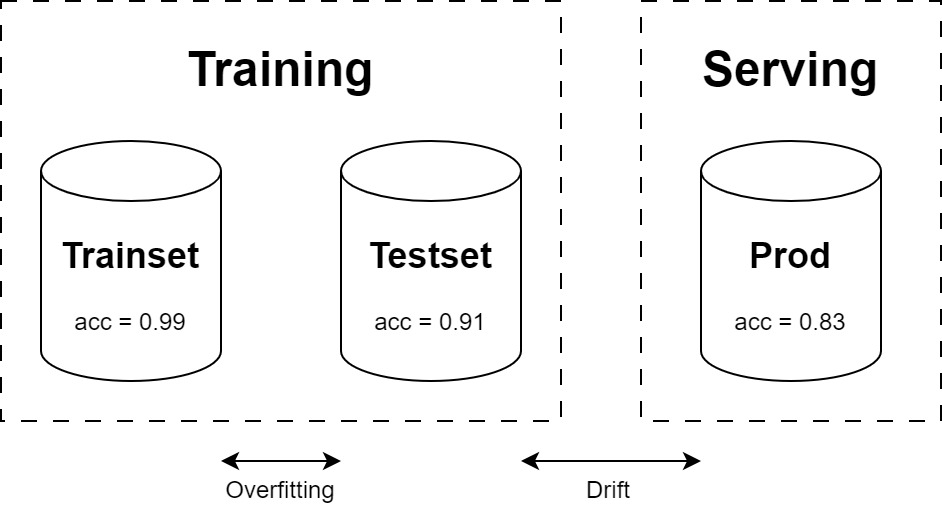
Fig 1: Traditional Evaluation Framework
But this same approach doesn’t work for LLMs. This is because the traditional approach is based on two key pillars, i.e., data and metrics. As LLMs are expensive to train, most applications resort to calling an external API, provided by the OpenAIs and Anthropics of this world. And, good luck with getting the data for these models. But even if one has trained their own LLM (hence, they have data), the question that looks us in the eyes is “what metrics to calculate for evaluation?”. The output of LLMs are more on the qualitative side and are hard to quantify. Another challenge is General-Purpose nature of LLMs. They can perform a diverse set of behaviours. Thus, aggregate metrics become more or less inefficient.
To summarise, there are three challenges in evaluating the LLMs:
- Access to training data
- Qualitative outputs, which are hard to quantify
- Diversity of behaviour
2. Makeshift evaluation framework for LLMs Link to heading
As discussed in the previous section, traditional evaluation strategy needed a dataset and a bunch of metrics to calculate on that dataset. So, building on this, we will divide our approach into two steps:
- What dataset to use?
- What metrics to measure?
2.1. Evaluation dataset Link to heading
A dataset is any set of records. As opposed to the supervised paradigm of model training, we don’t have input-output pairs to begin with. So, we will have to compile our own data. To do so, we can follow the following three-step strategy.
2.1.1. Look out for interesting cases Link to heading
The best way to prepare the dataset is to just start. Accumulate the ad hoc prompts that you use. For instance, write a short paragraph about subject. Here, the subject could be anything, from an inanimate object to a pet.As you are firing these prompts, there will be some unique and interesting cases where the LLM will fail to generate the “required” output and will require some tweaks in the prompt. You can consolidate these tricky, hard and unique examples into a small dataset.
2.1.2. Incrementally add more data Link to heading
As the LLM application is rolled out, we can start capturing the real time feedback from the users. This feedback could be handled in two ways:
- Explicit feedback: this sort of feedback is easier to capture. Here, we just ask the user whether he liked the answer generated or not. As OpenAI does, we can provide a thumbs-up and thumbs-down icon to collect this type of feedback.
- Implicit feedback: as opposed to explicit feedback, this feedback is relatively difficult to collect. One way to collect implicit feedback is to check if the user is asking the same question (different words but semantically having the similar meaning) multiple times.
Fig 2: Explicit Feedback in ChatGPT
Using explicit and implicit feedback, we can collect cases which users disliked the output for and add them to data created in the previous step. Also, we can look out for underrepresented topics, intents and documents (in other words, edge cases).
2.2. Evaluation metrics Link to heading
Evaluation metrics estimates how well the model predictions reflect the “Gold” outputs. The gold output here refers to the manually-curated outputs. As the outputs of LLMs are text or images, comparing the prediction with these labels isn’t as straightforward. As discussed earlier, the output of the LLMs is text or images, which are judged on the qualitative properties. Because of which, entirely getting rid of human-evaluation would be difficult. But, our aim should be to reduce the involvement as much as possible.
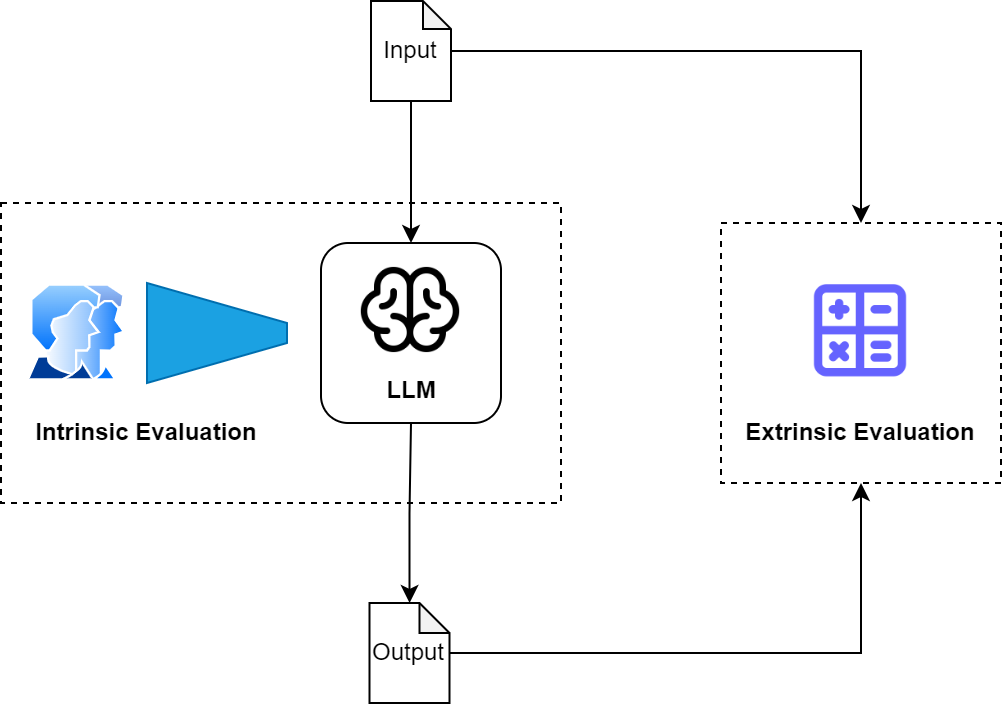
Fig 3: Types of LLM evaluation
As illustrated in the diagram above, an LLM can be evaluated either intrinsically or extrinsically. In brief,
- Intrinsic evaluation: looks into the internals of the LLM. For instance, understanding how it embeds words of different types, or how it implies biases etc.
- Extrinsic evaluation: evaluates the LLM by providing input to the model in a systematic way and analyses the output generated by these inputs.
As LLMs can perform a wide range of tasks, there is a need for multiple metrics on which they should be evaluated. Here, we will discuss a few metrics that are commonly used.
2.2.1. Bias and Fairness Link to heading
Bias is a systematic error that results in an unfair model. In LLMs, this systematic error could result in prejudice against a person or a group of people. Such behaviours are particularly harmful if targeted towards personal attributes, such as gender, race or sexual orientation. For instance, Caliskan et al (2017) highlighted that the European-American names were more closely Associated with pleasant words than the African-American names.
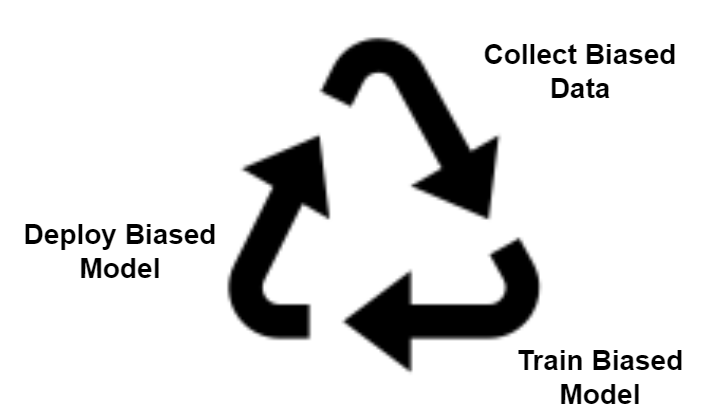
Fig 4: Bias Cycle
The bias can be originating from various parts of the application, so it is important to evaluate the whole application rather than just the LLM:
- LLM bias: Given the input response, how often will the model generate a toxic or biassed response?
- System bias: There could be cases where the model itself is fair, but the translation technology it uses is generating incorrect information. For instance, stereotyped genders.
While the LLMs might have inherent bias which might be difficult to remove, it is also better to have infrastructure around the model with the constraint filters. Such systems can be tested in natural settings, in which they are actually deployed. For evaluation, the following bias generation frameworks can be used:
2.2.2. Toxicity Link to heading
Toxicity (or neural toxic degeneration) is the generation of rude or disrespectful text. If a LLM is generating such unintended text, it can affect users, which might include young or vulnerable users.To evaluate LLMs on toxicity, Real Toxicity Prompts can be used in cadence with the Perspective API, using the following framework:
- Prompt the model k times, and collect the responses.
- Use Perspective API to calculate the score for each generation.
- Report maximum and average toxicity rate over all examples.
2.2.3. Factuality Link to heading
Factuality refers to truthfulness of information provided. As the LLMs are increasingly being used for generating text, we would like to eliminate any disinformation they emanate. Despite their impressive open-ended text generation, LLMs, under the hood, rely on statistical correlation between subword tokens, leading to limitation of generation of factually inaccurate information.
To illustrate the point, sometime back in 2023, I asked ChatGPT to generate a bio of an Indian-Origin Cricketer who plays for New Zealand. But, it provided incorrect information about his country of origin.
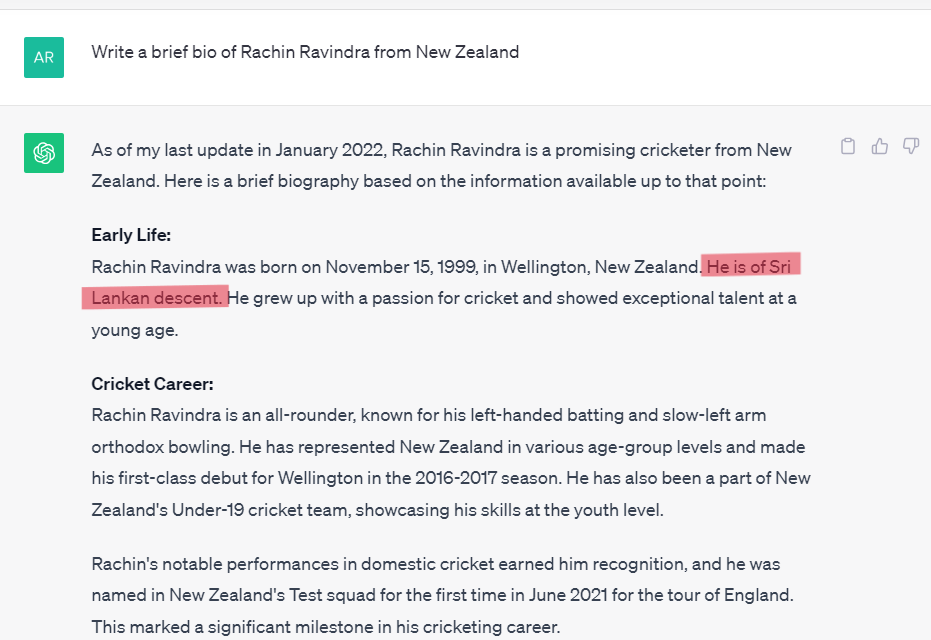
Fig 5: Factually incorrect information
The evaluation of factuality depends heavily on having correct “ground-truth” knowledge as a reference. While one can use datasets such as Wiki-Data for evaluation of public information, it becomes increasingly complex and difficult when working on the closed-domain use-cases.
Conclusion Link to heading
While LLMs succeed in creating coherent, contextually relevant, and logically consistent narratives or responses without predefined endings or constraints, it is still a challenge to generate outputs that remain factual, reliable and free of toxic content. While there are techniques available to evaluate these metrics, a framework about their use and application is still not available.